Hello, You are on InfoCompile. You are here to read about Search Engine Crawling i.e. important to know for webmasters. So what is crawling, SEO masters should know this. By the end of this article, you will get the answer on “What is Search Engine Crawling & why SEO masters should know about this?
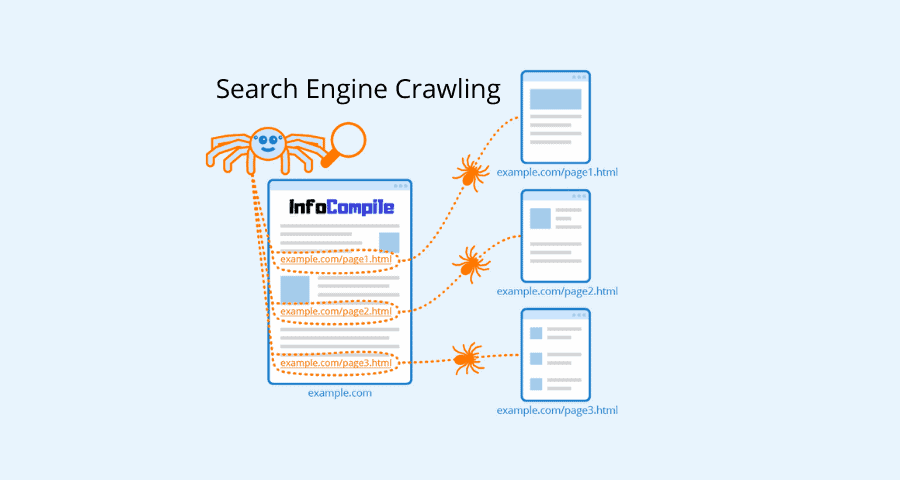
Crawling is the name of the process practised by search engine web crawlers. These web crawlers sometimes called bots or spiders. These bots visit and scan content on the page and also extract its links to fetch additional pages linked to the content.
Once the pages are identified by the search engines, they start crawling them periodically. Search engines use periodic crawling. They do so to check any modifications made to the content of page since the last time it was crawled. If a search engine identifies any changes to a page after crawling, it updates its search index in the response to identified changes.
If you have not got the meaning yet, then check this easy explanation.
A different explanation
Crawling takes place when search engines throw a bot to a web post or web page in order to fetch information from the page. This is what that Google Bot or various crawlers do, to determine what is on the page. Many people have queries with definitions of crawling and indexing. Both are the separate processes, don’t get confused. Whereas Crawling is the fundamental process of recognising pages by a search engine.
Do you know that the pages are crawled by search engines for a variety of reasons including:
- Having an XML sitemap
- Getting a spike in traffic to the page
- Having internal links pointing to the page
- Having external links pointing to the page
To assure that your webpage gets crawled, you should produce an XML sitemap and the should be uploaded to Google Search Console to provide Google with the roadmap for all of your content on the website.
Nice